Beyond Porting: How vLLM Orchestrates High-Performance Inference on AMD ROCm
Introduction
For a long time, enabling AMD support meant “porting”: just making code run. That era is over.
With AMD CDNATM 3 architecture hardware (AMD InstinctTM MI300X, Instinct MI325X, Instinct MI355X GPUs) and complex model structures like DeepSeek’s MLA, “just running” isn’t enough. These workloads demand architectural co-design, where software orchestration and hardware primitives work together.
vLLM now provides 7 attention backends on AMD ROCmTM software. This post explains each one: why they exist, their trade-offs, and when to use them. We provide transparent benchmarks comparing all backends, and show how ROCM_AITER_FA for MHA and the AITER MLA backends deliver 1.2-4.4x higher throughput (TPS) through AMD’s AITER primitives and vLLM’s kernel orchestration.
The Challenge: Mixed Workloads in Every Batch
In production LLM serving, each inference step processes a mixed batch of tokens from different request types. The industry has recognized this challenge—various solutions exist, from unified kernels with sophisticated internal scheduling to multi-path routing with specialized kernels. AMD’s ROCM_AITER_FA takes the explicit routing approach, making workload-aware optimization a first-class design principle rather than an internal kernel detail.
-
Prefill: New prompts arriving at the server. These contain thousands of input tokens that need attention computation all at once. The GPU is doing heavy matrix multiplication here, making prefill compute-bound.
-
Decode: Generating output tokens one at a time. Each decode step loads the entire KV cache from memory to produce a single token. The bottleneck is memory bandwidth, making decode memory-bound.
-
Extend: Continuing conversations where part of the context is already cached (prefix cache hit). This is a hybrid scenario where new tokens must attend to both cached context and fresh input.
These request types arrive randomly and are batched together for efficiency.
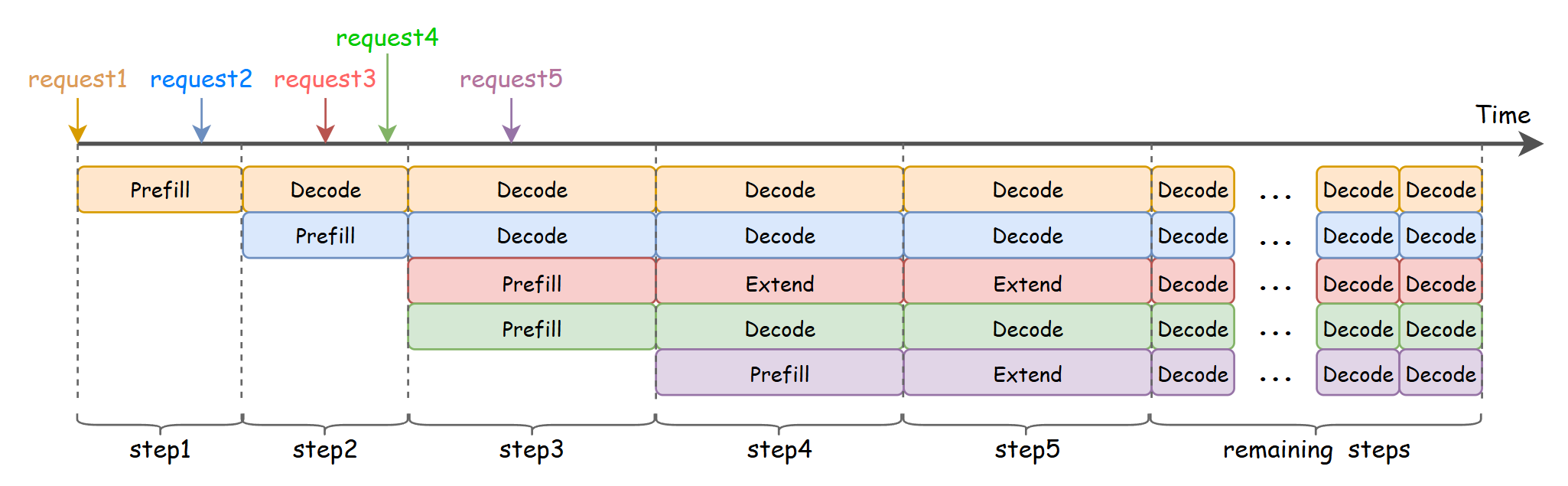
Online serving with 5 concurrent requests. Step 4 shows prefill, extend, and decode tokens batched together.
The optimization challenge: prefill wants large tile sizes and maximum ALU utilization, while decode wants coalesced memory access and minimal cache fetches. A kernel tuned for one workload leaves performance on the table for the other.
This mixed-workload scenario is exactly what ROCM_AITER_FA’s 3-path routing addresses: instead of forcing all request types through one kernel, it routes each type to a specialized kernel optimized for that workload’s characteristics.
Other MHA Backends
Before diving into ROCM_AITER_FA, let’s understand the other MHA backends available:
Unified Attention Backends
These backends process all tokens (prefill/extend/decode) through a single kernel path:
| Backend | Kernel Source | Use Case |
|---|---|---|
| TRITON_ATTN | vLLM Triton kernel | Default fallback |
| ROCM_AITER_UNIFIED_ATTN | AITER Triton kernel | Single-kernel AITER path |
def forward():
# Stage 1: Save Key/Value into KV-Cache
reshape_and_cache_flush(new_key, new_value, ...)
# Stage 2: Single kernel for all attention
unified_attention_kernel(new_query, KV-Cache, ...)
ROCM_ATTN: Legacy 2-Path Backend
ROCM_ATTN uses 2-path routing with different kernels per phase:
- Prefill: Triton kernel
- Decode: HIP paged attention kernel (when supported)
This backend has two important characteristics:
-
Legacy 2-path architecture: Uses separate kernels for prefill (Triton) and decode (HIP paged attention). Note that the HIP paged attention kernel only supports certain KV head sizes—for unsupported configurations (like Qwen3-235B), it falls back to Triton decode kernels, resulting in significantly slower performance.
-
Radeon GPU support: Along with
TRITON_ATTN, this backend supports Radeon GPUs—useful for consumer hardware deployments where AITER primitives aren’t available.
The ROCM_AITER_FA Backend: Kernel Orchestration for AMD
ROCM_AITER_FA isn’t just a kernel wrapper—it’s a sophisticated orchestration layer that routes requests to specialized kernels, combining vLLM’s high-level management with AMD’s AITER primitives.
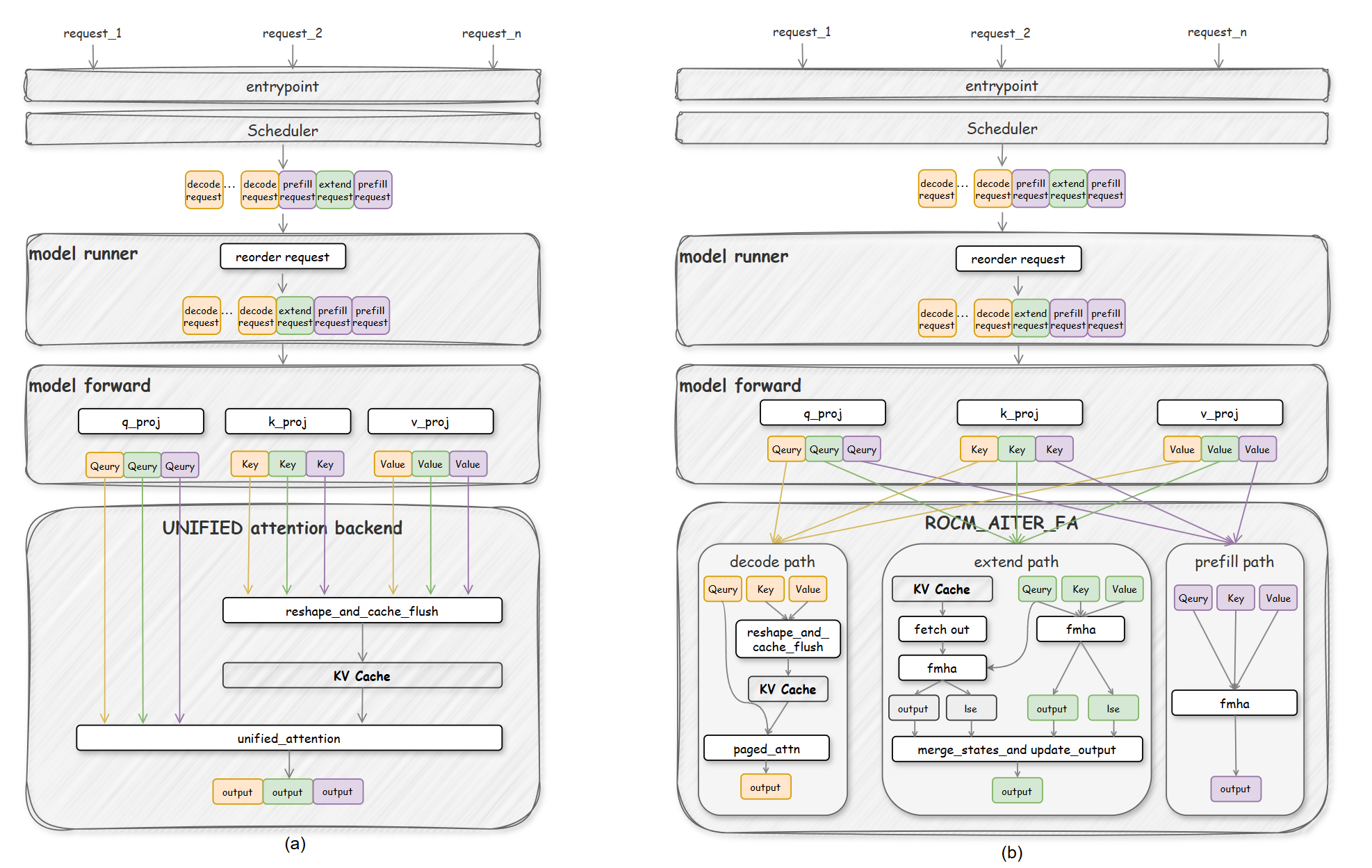
(a) Unified attention processes all tokens through one kernel. (b) ROCM_AITER_FA routes tokens to three specialized paths.
Key Innovations
1. Three-Path Routing: Requests are dynamically categorized into Decode, Prefill, and Extend paths—each with optimized kernels:
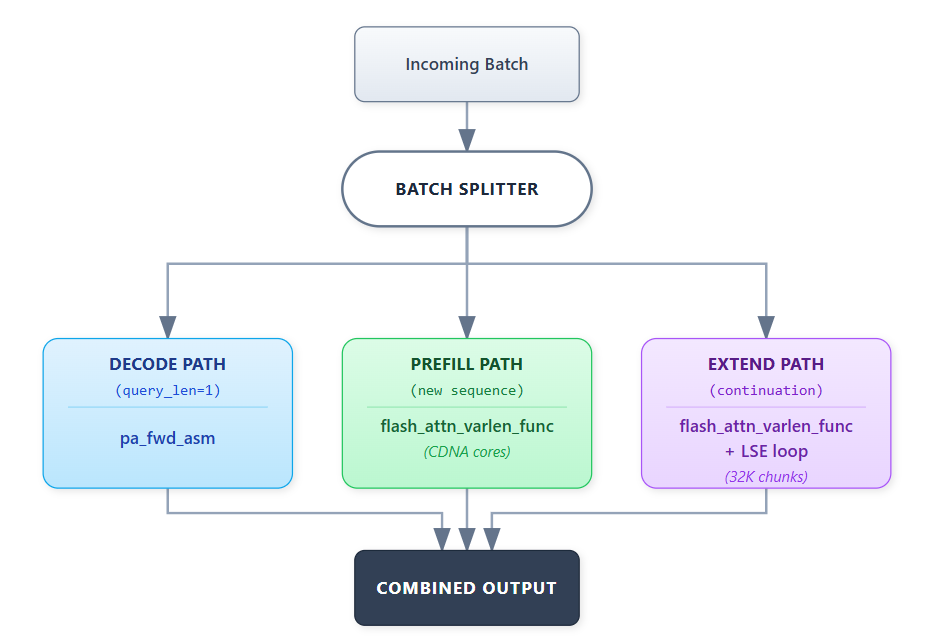
Each path uses specialized kernels optimized for its workload characteristics.
- Decode: Single token generation uses AITER highly optimized kernel for memory bandwidth
- Prefill: New sequences use
flash_attn_varlen_func—leveraging CDNA matrix cores for compute-heavy work - Extend: Continuing sequences use chunked attention with LSE merging—handling 100K+ contexts efficiently
Animation: R1 (decode token) routes to Decode Path, R2 (prefill tokens) routes to Prefill Path.
2. Batch Reordering: Requests are reordered to [decode:extend:prefill] for contiguous memory access, eliminating redundant KV cache fetches.
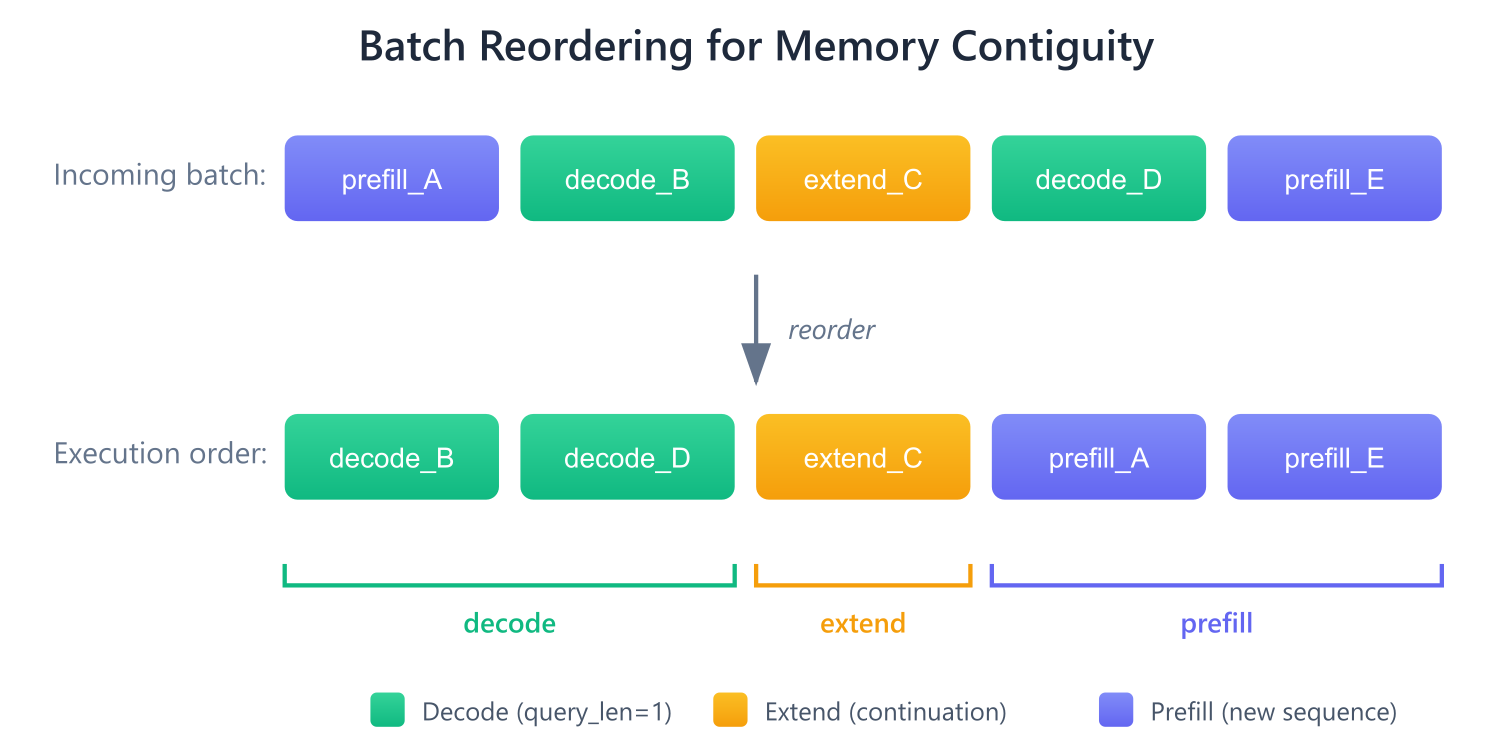
Batch reordering ensures each kernel path operates on contiguous tokens, eliminating redundant KV cache fetches.
Animation: Batch reordering reorders requests to [decode > extend > prefill], then routes R3 to Extend Path.
3. Chunked Context Processing: Long sequences are processed in chunks sized by a fixed per-iteration token budget (~32K tokens total), split across extend requests; LSE-based merging ensures numerical stability.
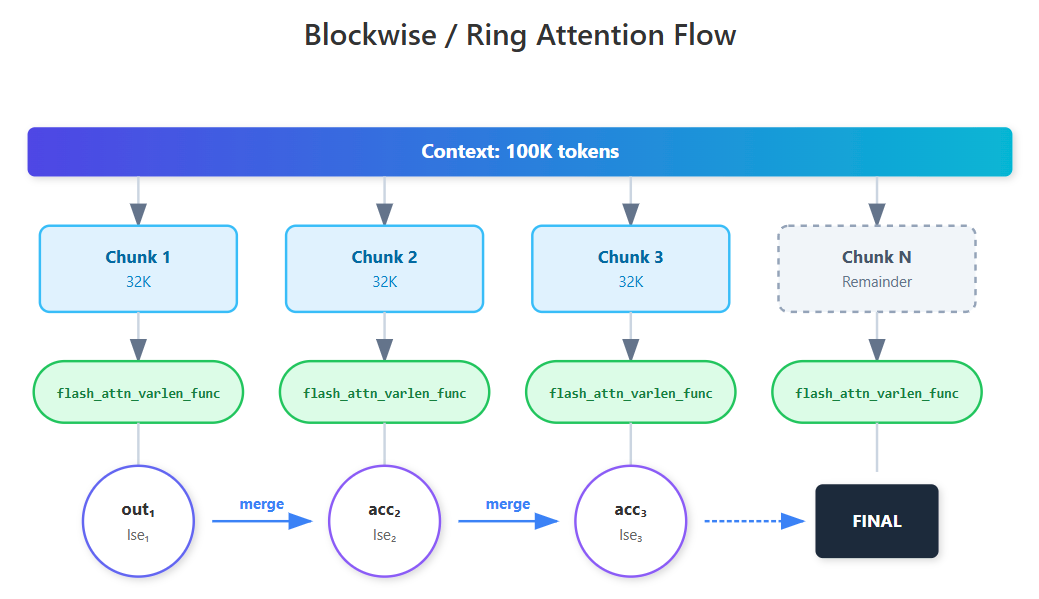
100K+ token contexts are processed in 32K chunks with LSE-based merging for numerical stability.
4. Hardware-Optimized KV Cache Layout: Uses a preshuffled KV cache layout designed by AMD’s AITER kernel team:
k_cache: [num_blocks, num_heads, head_dim // x, block_size, x]
v_cache: [num_blocks, num_heads, block_size // X, head_dim, X]
This layout aligns memory access patterns with AMD’s CDNA architecture, enabling the decode path to call AITER’s pa_fwd_asm kernel with zero layout conversion overhead—delivering 15-20% decode throughput improvement compared to standard KV cache layouts.
Why Explicit 3-Path Routing?
ROCM_AITER_FA makes a deliberate architectural choice: route workloads at the software layer rather than relying on a single kernel to handle everything.
This explicit approach offers:
- Debuggability: Each path can be profiled, tuned, and optimized independently
- Portability: The same routing logic works across MI300X → MI325X → MI355X without hardware-specific changes
- Extensibility: New workload types or kernel variants can be added without redesigning the core architecture
- Predictability: Execution paths are deterministic, making performance analysis straightforward
The extend path is particularly important: prefix caching and multi-turn conversations are now standard in production deployments. Having a dedicated path with chunked context attention ensures these workloads get first-class optimization.
Three-Path Processing in Detail
Decode Path: Leverages the shuffled KV cache layout directly. A custom reshape_and_cache_flush operator ensures the cache is always in the shuffled layout, allowing the attention backend to call AITER’s performant pa_fwd_asm kernel with zero layout conversion overhead.
Prefill Path: Query/Key/Value are in the standard [num_tokens, num_heads, head_dim] layout to align with the highly optimized AITER MHA kernel and avoid any extra memory copy operations.
Extend Path: This is the most challenging path. New tokens must compute attention with context tokens stored in the shuffled KV cache layout. Since the shuffled layout is incompatible with AITER’s MHA kernel for long-context computation, we insert an extra KV Cache fetching operator (cp_mha_gather_cache) to fetch and convert context Key/Value to standard layout. Long contexts are chunked into segments to manage memory:
def extend_forward():
# Stage 1: Attention for new tokens
flash_attn_varlen_func() # calling AITER MHA
# Stage 2: Context Chunk Loop Processing
for chunk in context_chunks:
cp_mha_gather_cache() # Triton gather kernel
flash_attn_varlen_func() # calling AITER MHA
merge_attn_states() # LSE-based merge
# Stage 3: Get the final result
merge_attn_states()
Each chunk produces an output and LSE (log-sum-exp). The LSE captures the softmax denominator, enabling numerically stable merging—chunks with higher attention scores naturally dominate the final result.
Interactive Animation: ROCM_AITER_FA Request Flow
The following animation demonstrates how multiple requests flow through the ROCM_AITER_FA backend across 7 iterations. Use the controls to start, pause, or jump to specific iterations.
Iteration Guide:
| Iteration | Key Events |
|---|---|
| 1 | R1 enters → tokenization → scheduler queue → QKV projection → Prefill Path → sample 1 token. R2 arrives mid-iteration, waits in queue. |
| 2 | R1 + R2 batched together. R1 → Decode Path, R2 → Prefill Path. R3, R4 arrive and enter queue. |
| 3 | 4 requests batched. Token budget = 100, so R3 schedules 100 tokens (180 remaining). R3 output = 0 (not all prompt tokens computed yet). |
| 4 | R3 enters Extend Path to continue computing remaining prompt tokens. Batch reordering: tensors reordered to [decode > extend > prefill]. |
| 5 | Batch reordering continues: [decode > extend] order. R5 finishes extend, transitions to decode. |
| 6-7 | All requests in Decode Path, generating tokens until stop signal. |
The animation shows how ROCM_AITER_FA dynamically routes requests through Prefill → Extend → Decode paths based on their state, enabling efficient batched processing of mixed workloads.
The AITER MLA Backends: Optimized for DeepSeek
DeepSeek and Kimi’s MLA architecture compresses the KV cache to 576 dimensions (vs ~8K for standard MHA)—a 14x memory reduction. This compression changes the performance characteristics of attention, requiring a different optimization strategy than standard MHA.
The Hybrid Approach
vLLM provides two AITER-based MLA backends with different prefill implementations:
| Backend | Prefill Kernel | Decode Kernel |
|---|---|---|
TRITON_MLA |
vLLM Triton | vLLM Triton |
ROCM_AITER_MLA |
AITER MHA (CK on gfx942, ASM on gfx950) | AITER Assembly |
ROCM_AITER_TRITON_MLA |
AITER Triton MHA | AITER Assembly |
The base TRITON_MLA backend uses vLLM’s default Triton kernels for both phases. The AITER backends replace the decode kernel with hand-tuned assembly (mla_decode_fwd), which is where most of the performance gain comes from. The only difference between the two AITER backends is the prefill path: ROCM_AITER_MLA calls aiter.flash_attn_varlen_func (AITER MHA), while ROCM_AITER_TRITON_MLA calls aiter.ops.triton.mha.flash_attn_varlen_func (AITER Triton MHA). On gfx942 (MI300X/MI325X GPUs), AITER MHA resolves to CK kernels; on gfx950 (MI355X), it resolves to the newer assembly MHA kernels.
Why the prefill winner flips by architecture? Two reasons:
-
gfx942 (MI300X/MI325X): XCD-aware scheduling: The AITER Triton kernel explicitly remaps head distribution across XCDs via
remap_xcd(), ensuring balanced load. The CK path doesn’t expose this logic at the Python level. -
gfx942 (MI300X/MI325X): Runtime config flexibility: Triton selects architecture-specific configs at runtime (e.g.,
BLOCK_M=128, BLOCK_N=64for MI300X), while CK uses a fixed set of pre-generated kernels.
On gfx950 (MI355X), AITER MHA switches to the assembly kernel, which is hand-tuned for the MI355X GPU and tends to beat the Triton MHA path. That is why ROCM_AITER_MLA often pulls ahead on TTFT even when TPOT stays close.
Absorbed vs Non-Absorbed Recipe
All MLA backends use the same fundamental processing strategy:
- Prefill/Extend (Non-Absorbed): Compute attention with standard MHA kernels on the uncompressed representation
- Decode (Absorbed): Use specialized MLA kernels operating directly on the compressed 576-dim latent space
def _forward_prefill():
# Stage 1: Attention for new tokens (non-absorbed)
_run_prefill_new_tokens()
# Stage 2: For extend path, context chunk loop
for chunk in context_chunks:
gather_and_maybe_dequant_cache()
_run_prefill_context_chunk()
merge_attn_states()
# Stage 3: Final merge
merge_attn_states()
During decode, the model generates one token at a time. The compressed KV cache means less data to load, but you’re still bottlenecked by memory bandwidth—making decode memory-bound. The AITER assembly kernel (mla_decode_fwd) maximizes every byte of HBM3 bandwidth, significantly outperforming generic Triton decode kernels.
Why the Assembly Decode Kernel Matters
Both AITER MLA backends (ROCM_AITER_MLA and ROCM_AITER_TRITON_MLA) share the same assembly decode kernel (mla_decode_fwd). This is where most of the performance gain comes from:
| Phase | AITER MLA Backends | vLLM TRITON_MLA Baseline |
|---|---|---|
| Prefill | AITER MHA or Triton (varies) | Triton flash attention |
| Decode | Assembly mla_decode_fwd |
Triton decode_attention_fwd |
The 1.2-1.6x speedup primarily comes from the shared assembly decode kernel. Since TPOT is decode-heavy (1K iterations for OSL=1K), optimizing decode yields the largest throughput gains. The prefill kernel difference between the two AITER backends has minimal impact on overall performance.
Beyond raw kernel performance, these backends inherit the full feature set of FlashMLABackend, including FULL_AND_PIECEWISE CUDA graph support and MTP support. Another advantage is near-identical performance across virtually any KV cache block size—you can treat every token as prefix cache without worrying about performance penalties typically associated with fine-grained caching.
Performance Benchmarks
Benchmark Methodology: All benchmarks were run using rocm/vllm-dev:nightly_main_20260115 with ROCm 7.0.0. This is a nightly Docker image built from the main branch of https://github.com/vllm-project/vllm on January 15, 2026. We warmed up kernels with initial requests first; reported results exclude the first run to eliminate JIT compilation overhead.
Benchmark Server Commands (click to expand)
MHA Benchmark (Qwen3-235B):
export SAFETENSORS_FAST_GPU=1
export VLLM_ROCM_USE_AITER=1
export VLLM_RPC_TIMEOUT=1800000
export VLLM_ROCM_SHUFFLE_KV_CACHE_LAYOUT=1
# Choose backend: TRITON_ATTN, ROCM_ATTN, ROCM_AITER_FA, ROCM_AITER_UNIFIED_ATTN
ATTN_BACKEND="ROCM_AITER_FA"
model_path=Qwen/Qwen3-235B-A22B-Instruct-2507-FP8
vllm serve $model_path \
--tensor-parallel-size 8 \
--max-num-batched-tokens 16384 \
--trust-remote-code \
--no-enable-prefix-caching \
--enable-expert-parallel \
--disable-log-requests \
--gpu_memory_utilization 0.9 \
--attention-backend ${ATTN_BACKEND} \
--compilation-config '{"cudagraph_mode": "FULL_AND_PIECEWISE"}' \
--async-scheduling \
--port 1234
MLA Benchmark (DeepSeek-R1):
export SAFETENSORS_FAST_GPU=1
export VLLM_ROCM_USE_AITER=1
export VLLM_RPC_TIMEOUT=1800000
# Choose backend: TRITON_MLA, ROCM_AITER_MLA, ROCM_AITER_TRITON_MLA
ATTN_BACKEND="ROCM_AITER_MLA"
model_path=deepseek-ai/DeepSeek-R1-0528
vllm serve $model_path \
--tensor-parallel-size 8 \
--max-num-batched-tokens 16384 \
--trust-remote-code \
--no-enable-prefix-caching \
--disable-log-requests \
--gpu_memory_utilization 0.9 \
--attention-backend ${ATTN_BACKEND} \
--compilation-config '{"cudagraph_mode": "FULL_AND_PIECEWISE"}' \
--async-scheduling \
--port 1234
MHA Benchmark Results
| Model: Qwen3-235B-A22B-FP8, TP8 for Attention + EP8 for MoE | Workload: ISL=10K, OSL=1K, 64 & 128 concurrent requests |
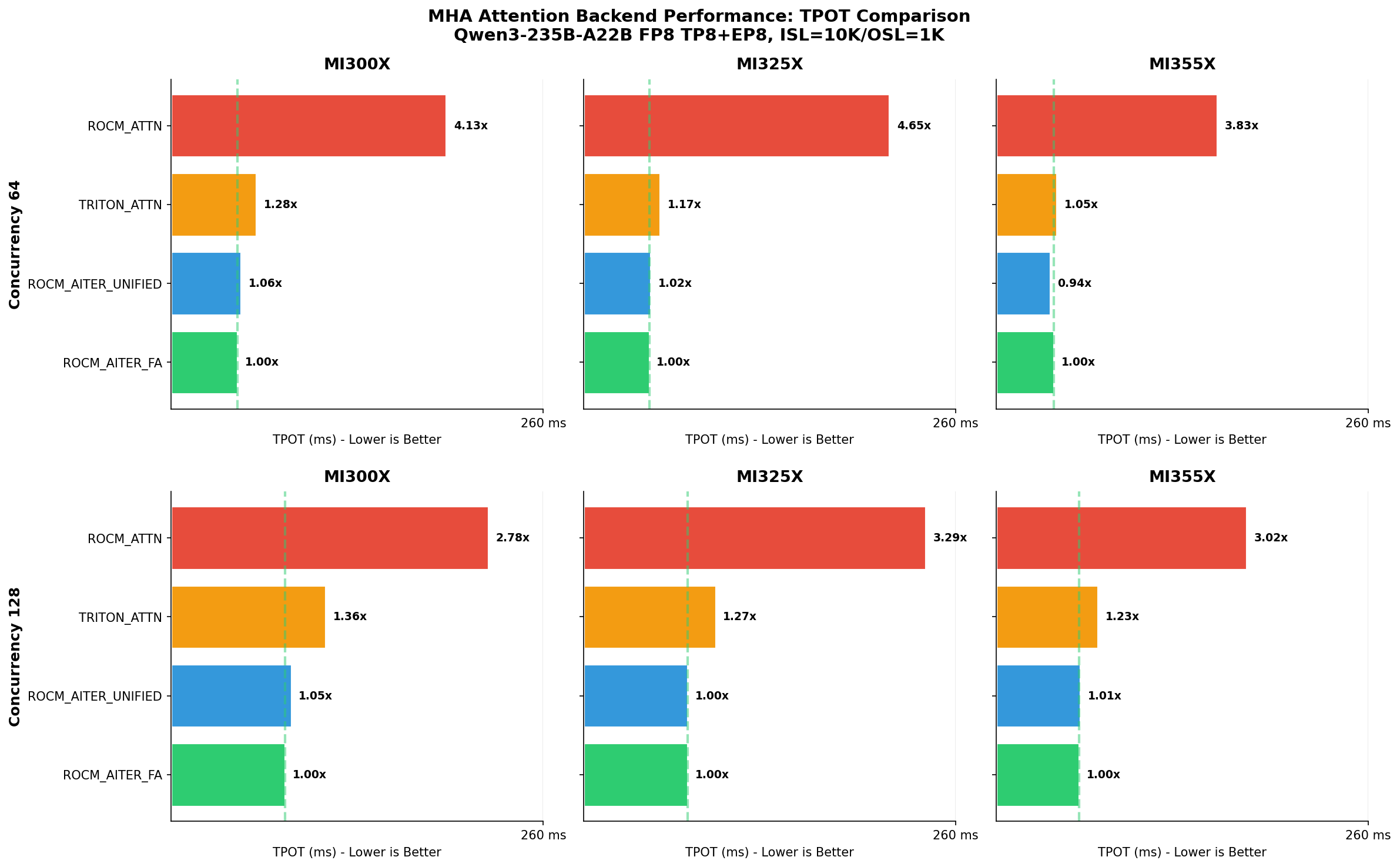 ROCM_AITER_FA delivers 2.8-4.6x faster TPOT compared to legacy ROCM_ATTN across MI300X/MI325X/MI355X.
ROCM_AITER_FA delivers 2.8-4.6x faster TPOT compared to legacy ROCM_ATTN across MI300X/MI325X/MI355X.
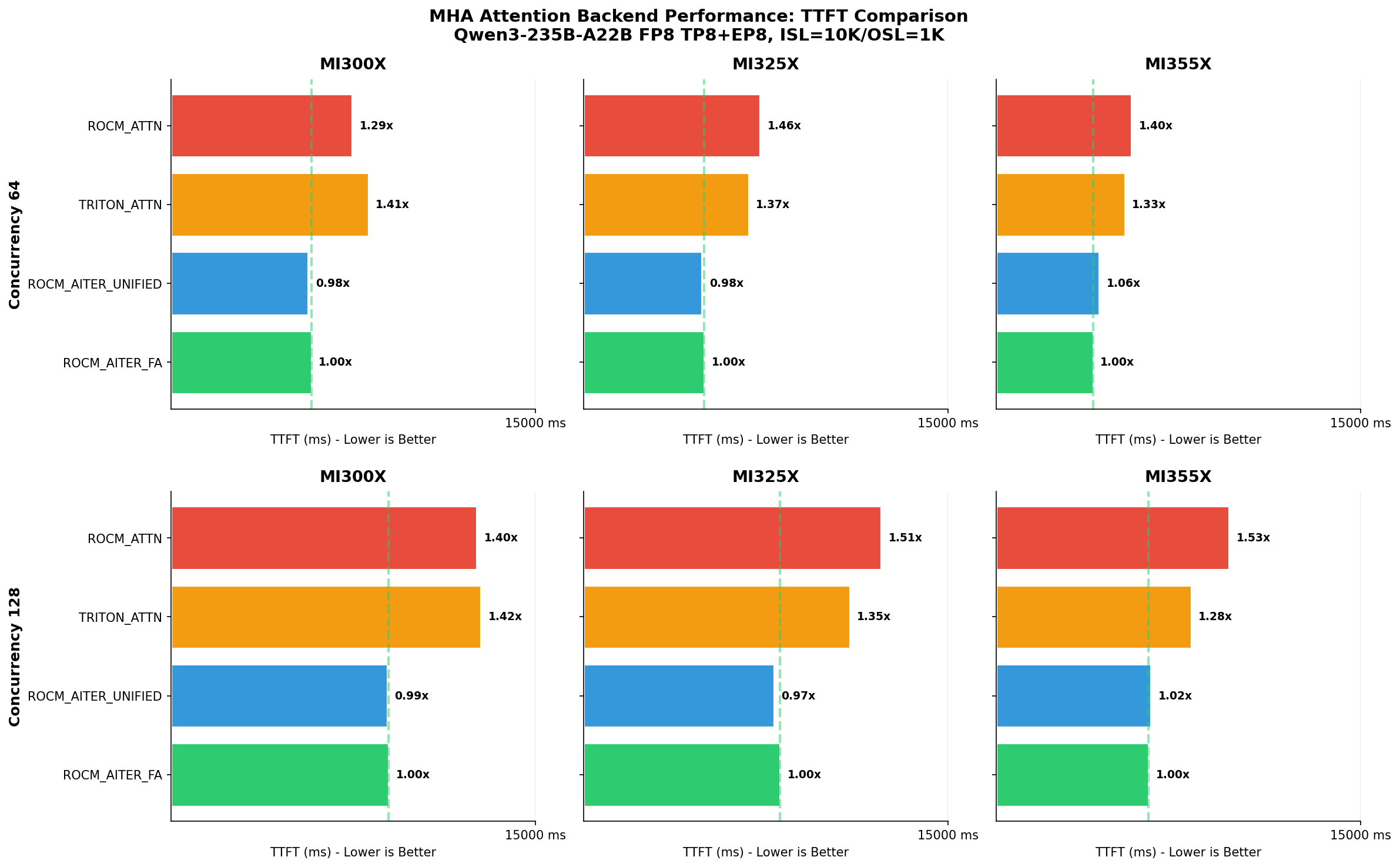 TTFT (Time To First Token) comparison shows ROCM_AITER_FA and ROCM_AITER_UNIFIED lead in prefill performance at 64 and 128 concurrency levels.
TTFT (Time To First Token) comparison shows ROCM_AITER_FA and ROCM_AITER_UNIFIED lead in prefill performance at 64 and 128 concurrency levels.
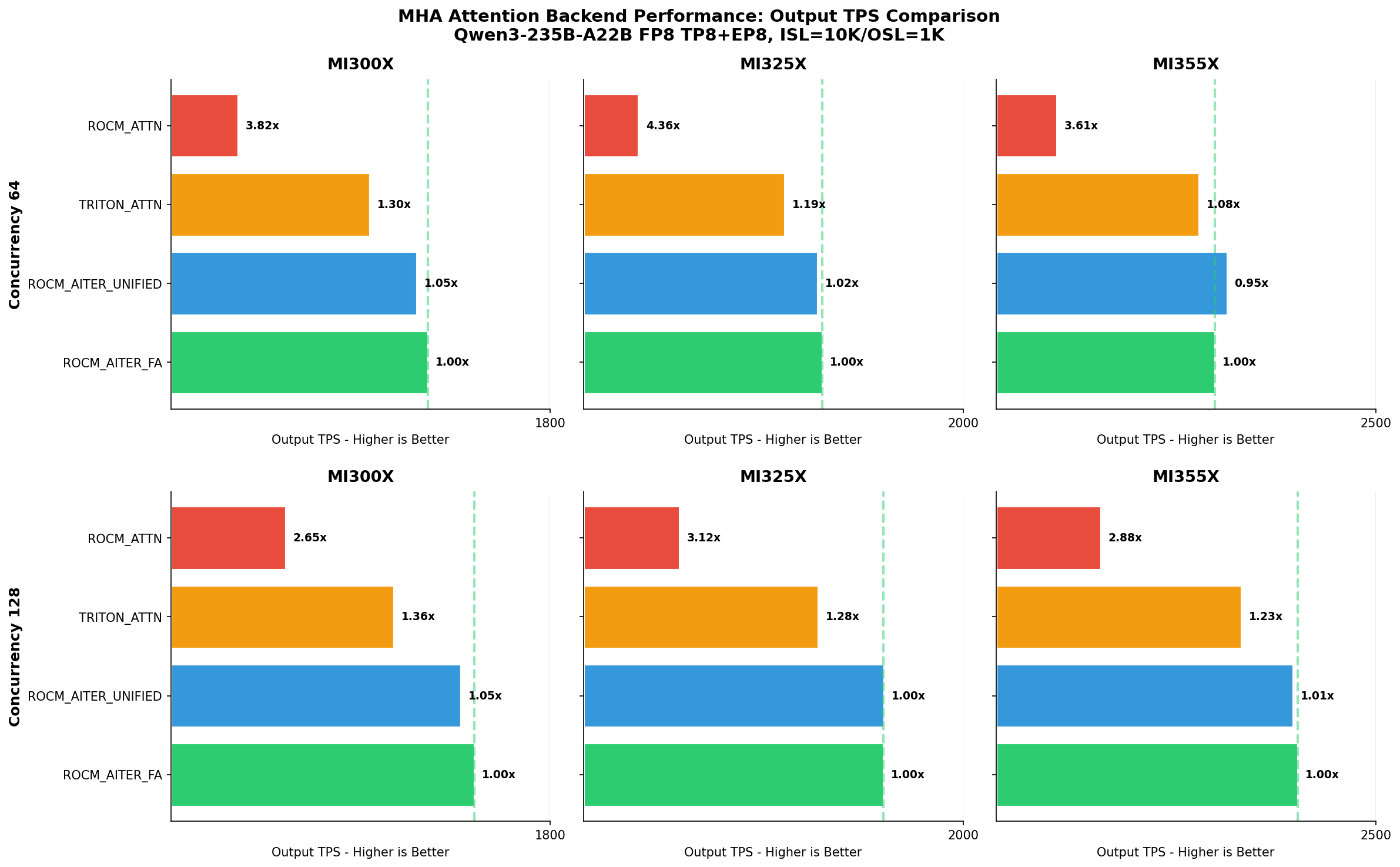 Output throughput (TPS) mirrors TPOT results—ROCM_AITER_FA achieves 2.7-4.4x higher throughput than legacy ROCM_ATTN.
Output throughput (TPS) mirrors TPOT results—ROCM_AITER_FA achieves 2.7-4.4x higher throughput than legacy ROCM_ATTN.
How many times slower in TPS vs ROCM_AITER_FA (64 concurrent requests):
| Hardware | ROCM_AITER_FA | ROCM_AITER_UNIFIED_ATTN | TRITON_ATTN | ROCM_ATTN |
|---|---|---|---|---|
| MI300X | 1.00x | 1.05x | 1.30x | 3.82x |
| MI325X | 1.00x | 1.02x | 1.19x | 4.36x |
| MI355X | 1.00x | 0.95x | 1.08x | 3.61x |
How many times slower in TPS vs ROCM_AITER_FA (128 concurrent requests):
| Hardware | ROCM_AITER_FA | ROCM_AITER_UNIFIED_ATTN | TRITON_ATTN | ROCM_ATTN |
|---|---|---|---|---|
| MI300X | 1.00x | 1.05x | 1.36x | 2.65x |
| MI325X | 1.00x | 1.00x | 1.28x | 3.12x |
| MI355X | 1.00x | 1.01x | 1.23x | 2.88x |
The relative performance is consistent across GPU generations. ROCM_AITER_UNIFIED_ATTN (single-kernel path) is within 5% of ROCM_AITER_FA (3-path routing) in this uniform workload scenario—the 3-path routing advantage would be more visible with mixed workloads containing prefix cache hits.
Note: ROCM_ATTN shows 2.7-4.4x slower TPS because Qwen3-235B has unsupported KV head sizes for HIP paged attention, forcing it to fall back to Triton decode kernels. ROCM_ATTN is faster than TRITON_ATTN for models with supported head sizes.
MLA Benchmark Results
| Model: DeepSeek-R1-0528, TP8, block_size=16 | Workload: ISL=10K, OSL=1K, 64 & 128 concurrent requests |
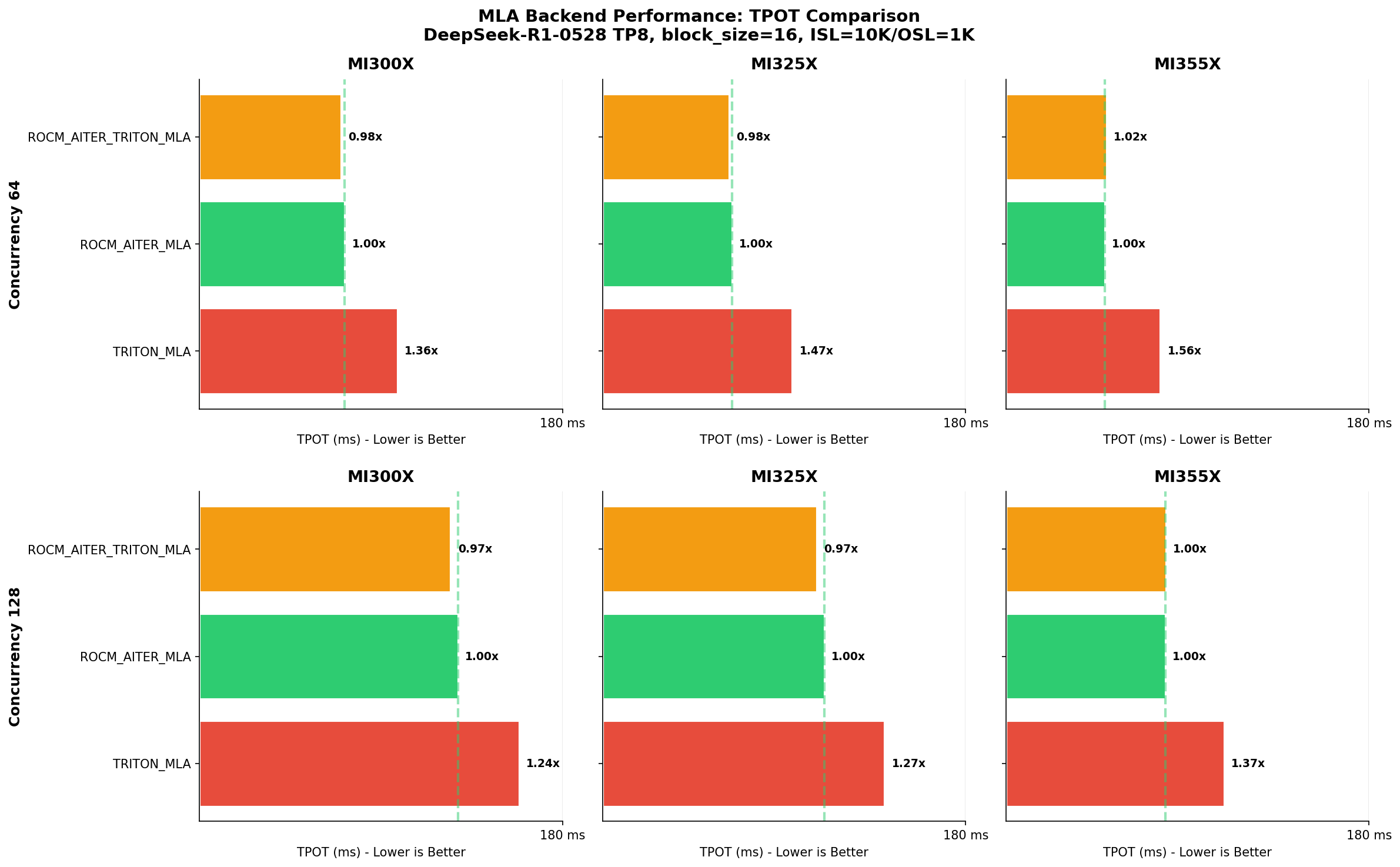 AITER MLA backends deliver 1.2-1.6x faster TPOT compared to TRITON_MLA across MI300X/MI325X/MI355X, thanks to the shared assembly decode kernel.
AITER MLA backends deliver 1.2-1.6x faster TPOT compared to TRITON_MLA across MI300X/MI325X/MI355X, thanks to the shared assembly decode kernel.
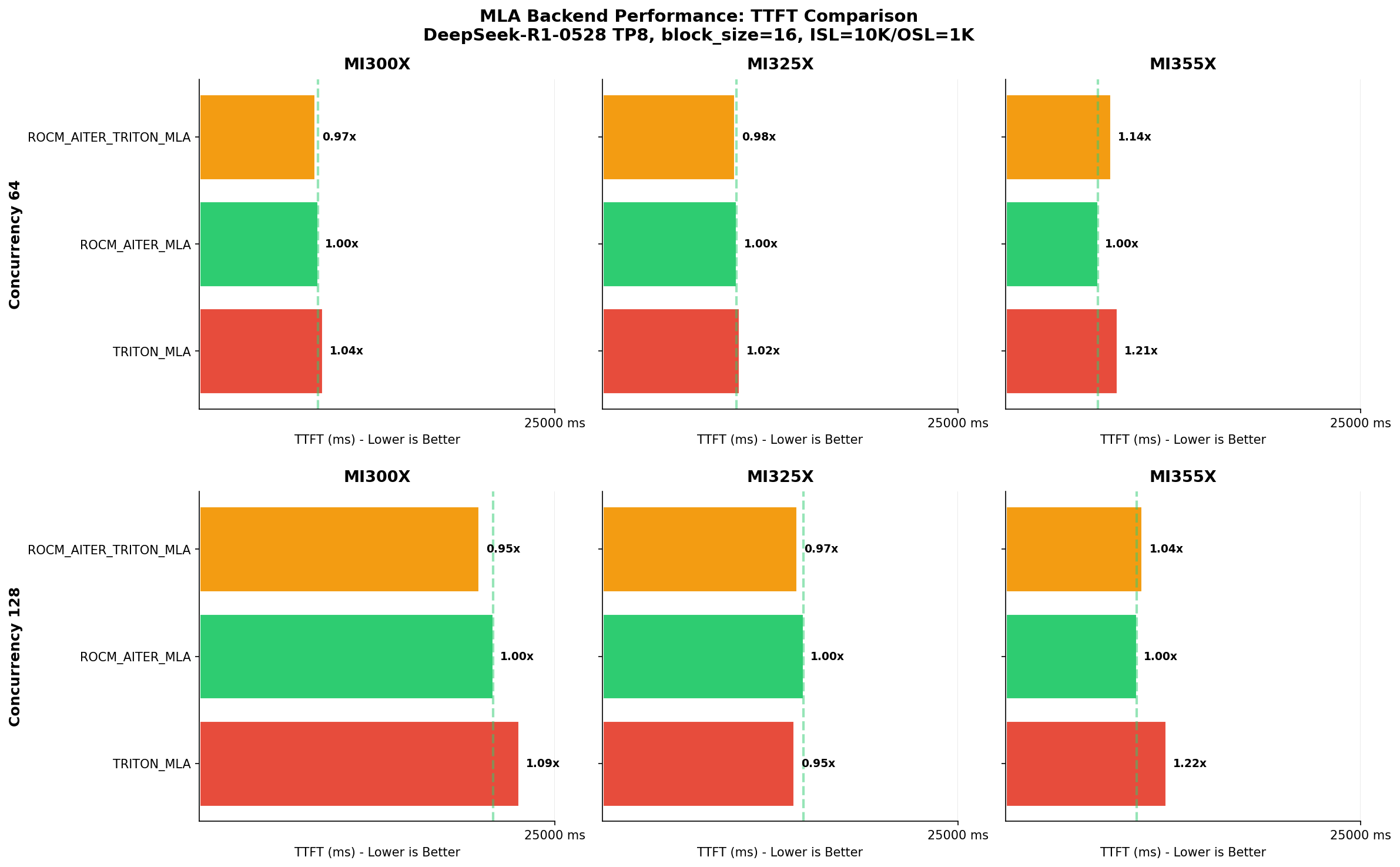 TTFT comparison shows ROCM_AITER_MLA achieves the best TTFT on MI355X at 128 concurrency.
TTFT comparison shows ROCM_AITER_MLA achieves the best TTFT on MI355X at 128 concurrency.
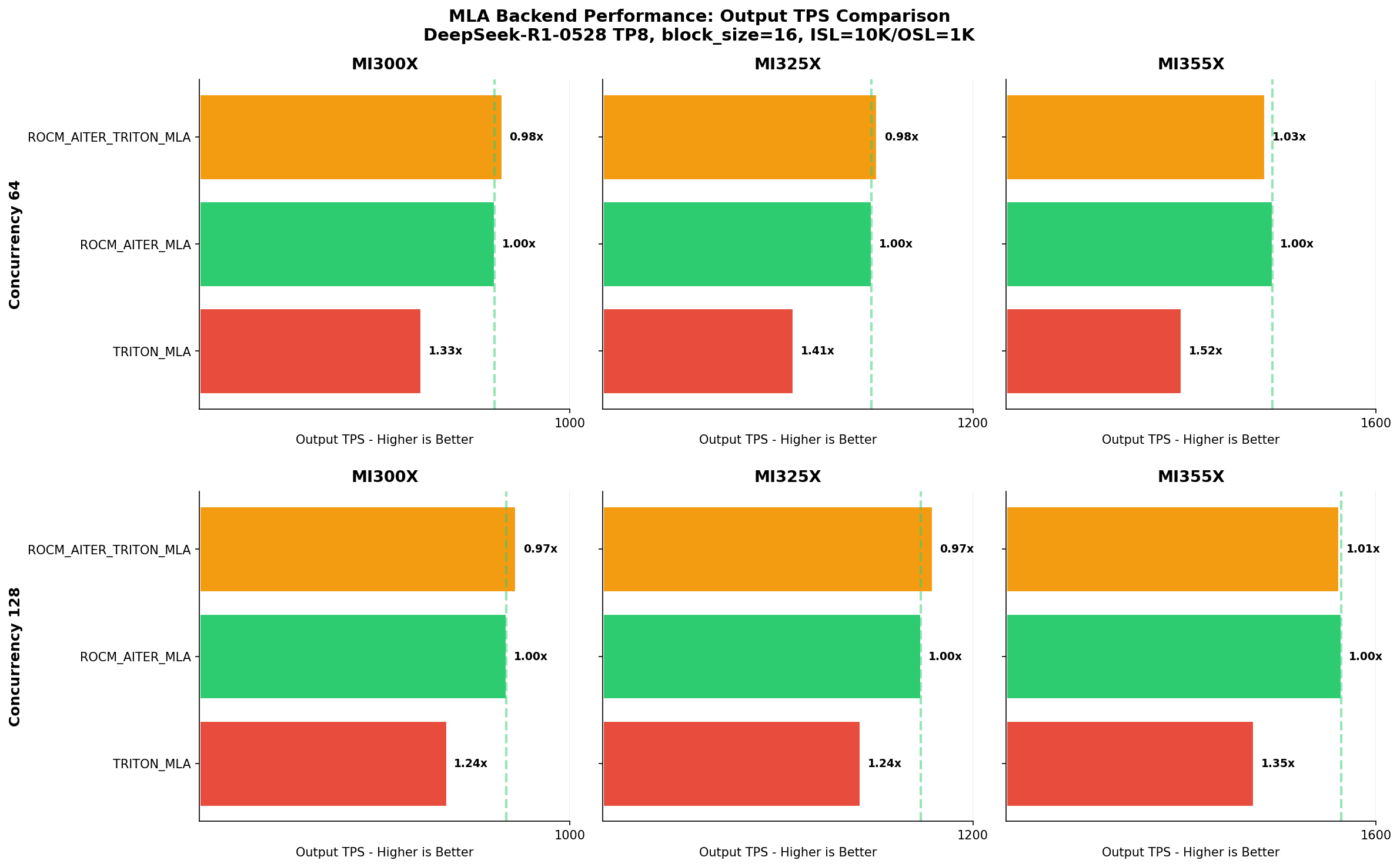 Output throughput (TPS) shows AITER MLA backends achieving up to 1.5x higher throughput than TRITON_MLA.
Output throughput (TPS) shows AITER MLA backends achieving up to 1.5x higher throughput than TRITON_MLA.
How many times slower in TPS vs ROCM_AITER_MLA (64 concurrent requests):
| Hardware | ROCM_AITER_MLA | ROCM_AITER_TRITON_MLA | TRITON_MLA |
|---|---|---|---|
| MI300X | 1.00x | 0.98x | 1.33x |
| MI325X | 1.00x | 0.98x | 1.41x |
| MI355X | 1.00x | 1.03x | 1.52x |
How many times slower in TPS vs ROCM_AITER_MLA (128 concurrent requests):
| Hardware | ROCM_AITER_MLA | ROCM_AITER_TRITON_MLA | TRITON_MLA |
|---|---|---|---|
| MI300X | 1.00x | 0.97x | 1.24x |
| MI325X | 1.00x | 0.97x | 1.24x |
| MI355X | 1.00x | 1.01x | 1.35x |
Both AITER MLA backends deliver similar overall performance. On gfx942 (MI300X/MI325X), ROCM_AITER_TRITON_MLA shows 2-3% higher TPS due to Triton beating CK in prefill. On gfx950 (MI355X), ROCM_AITER_MLA matches or beats ROCM_AITER_TRITON_MLA because it uses the AITER assembly MHA prefill. ROCM_AITER_MLA also achieves the best TTFT on MI355X. The auto-selected ROCM_AITER_MLA is recommended for all workloads.
Note: These benchmarks use uniform request sizes. Production workloads with prefix caching, mixed context lengths, and varied request patterns would exercise the 3-path routing architecture more fully.
The Collaboration: vLLM + AITER
The performance gains don’t come from a single optimization—they emerge from how vLLM’s orchestration layer and AMD’s AITER primitives work together. Understanding this collaboration explains why “just porting” falls short.

The complete system stack: from user request through vLLM orchestration to AITER primitives on AMD hardware.
Innovation Attribution
Where does the performance come from? Both layers working together:
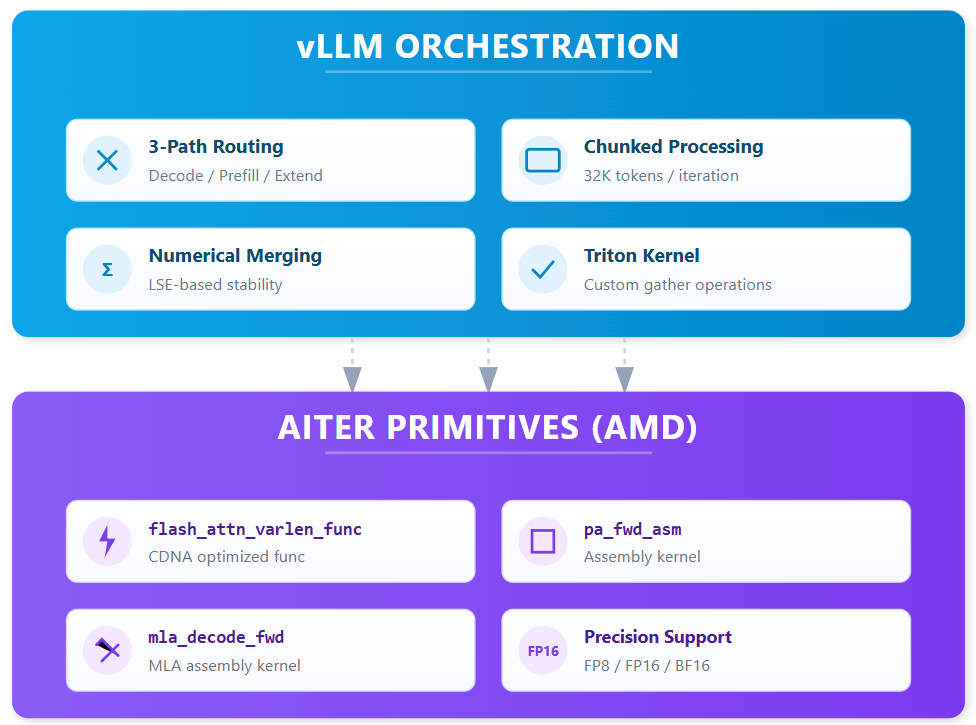 vLLM orchestration handles routing and chunking; AITER provides hardware-optimized primitives.
vLLM orchestration handles routing and chunking; AITER provides hardware-optimized primitives.
The key insight: AITER provides highly optimized attention primitives purpose-built for CDNA. vLLM’s orchestration layer adds workload-aware routing and chunked processing that unlock the final performance tier. Neither alone achieves optimal results.
Get Started
Quick Start
# Recommended: Let vLLM auto-select optimized backends
export VLLM_ROCM_USE_AITER=1
vllm serve <your-model> --tensor-parallel-size <tp>
With VLLM_ROCM_USE_AITER=1, vLLM automatically selects:
ROCM_AITER_FAfor MHA models (Llama, Qwen, Mistral)ROCM_AITER_MLAfor MLA models (DeepSeek, Kimi)
Selecting a Backend Explicitly
For advanced users who want to experiment, backends can be specified via --attention-backend:
vllm serve deepseek-ai/DeepSeek-R1-0528 \
--tensor-parallel-size 8 \
--attention-backend ROCM_AITER_TRITON_MLA
Our benchmarks show both AITER MLA backends deliver similar performance since they share the same assembly decode kernel. The prefill kernel differs slightly by architecture, but since decode dominates the workload, the overall difference is minimal. For most users, the auto-selected ROCM_AITER_MLA works well.
Hardware Support
| GPU | Memory | Architecture |
|---|---|---|
| MI300X | 192GB HBM3 | gfx942 |
| MI325X | 256GB HBM3e | gfx942 |
| MI355X | 288GB HBM3e | gfx950 |
Complete Backend Reference
vLLM provides 7 attention backends on AMD ROCm, each optimized for different scenarios:
| Category | Backend | How to enable | Notes |
|---|---|---|---|
| MHA | TRITON_ATTN | --attention-backend TRITON_ATTN |
Baseline, Radeon support |
| MHA | ROCM_AITER_UNIFIED_ATTN | --attention-backend ROCM_AITER_UNIFIED_ATTN |
AITER unified kernel |
| MHA | ROCM_ATTN | --attention-backend ROCM_ATTN |
Legacy 2-path, Radeon support |
| MHA | ROCM_AITER_FA | --attention-backend ROCM_AITER_FA + VLLM_ROCM_SHUFFLE_KV_CACHE_LAYOUT=1 |
Recommended, auto-selected with AITER |
| MLA | TRITON_MLA | --attention-backend TRITON_MLA |
Baseline, Radeon support |
| MLA | ROCM_AITER_MLA | --attention-backend ROCM_AITER_MLA |
Recommended, auto-selected with AITER |
| MLA | ROCM_AITER_TRITON_MLA | --attention-backend ROCM_AITER_TRITON_MLA |
Alternative AITER MLA backend |
Conclusion
The era of “just porting” is over. This post covered all 7 attention backends available on AMD ROCm in vLLM, with transparent benchmarks showing their trade-offs.
Key Results (ISL=10K, OSL=1K benchmark):
ROCM_AITER_FA: 2.7-4.4x higher TPS than ROCM_ATTN on MHA modelsROCM_AITER_MLA: 1.2-1.5x higher TPS than TRITON_MLA on DeepSeek MLA via assembly decode kernel- Performance scales across MI300X → MI325X → MI355X
Our recommendation: Simply use export VLLM_ROCM_USE_AITER=1 and let vLLM auto-select the optimal backends. The defaults (ROCM_AITER_FA for MHA, ROCM_AITER_MLA for MLA) deliver excellent performance across all tested workloads.
This is what native AMD optimization looks like: not ported, purpose-built. The 3-path routing architecture reflects a deliberate design choice—explicit workload separation at the software layer, with each path calling hardware-optimized AITER primitives. The result is a system that’s debuggable, portable across GPU generations, and ready for the mixed workloads of production LLM serving.
Acknowledgements
We would like to thank the many talented people who have contributed to this collaborations:
AMD: Hattie Wu, Yi Gan, Zejun Chen, Carlus Huang, Lingpeng Jin, Peng Sun and the AITER team.
Embedded LLM: Pin Siang Tan, Tun Jian Tan, Jun Kang Chow, and the Embedded LLM team.
Resources
Disclaimer
Testing by AMD AI Framework team as of Jan. 29, 2026, measuring the inference performance in TPS on AMD Instinct MI300X, MI325X, MI355X platforms.
Hardware Configuration
-
MI300x: AMD EPYC 9654 96-Core Processor server with 8x AMD Instrinct MI300X (192GB, 750W) GPUs, Supermicro AS-8125GS-TNMR2, NPS1 (1 NUMA per socket), 2.2TiB (24 DIMMs, 4800 mts memory, 96 GiB/DIMM), BIOS version: 3.2
-
MI325X: AMD EPYC 9575F 64-Core Processor server with 8x AMD Instrinct MI325X (256GB, 1000W) GPUs, Supermicro AS-8125GS-TNMR2, NPS1 (1 NUMA per socket), 2.2TiB (24 DIMMs, 4800 mts memory, 96 GiB/DIMM), BIOS version: 3.2
-
MI355X: AMD EPYC 9575F 64-Core Processor server with 8x AMD Instrinct MI355X (288GB, 1400W) GPUs, Supermicro AS-8125GS-TNMR2, NPS1 (1 NUMA per socket), 2.2TiB (24 DIMMs, 4800 mts memory, 96 GiB/DIMM), BIOS version: 3.2
Software Configuration(s) Ubuntu 22.04LTS with Linux kernel 5.15.0-116-generic, ROCm 7.0 version SW, PyTorch 2.9.0a0, vLLM 0.14.0rc2 (from Jan 15, 2026)
Server manufacturers may vary configurations, yielding different results. Performance may vary based on configuration, software, vLLM version, and the use of the latest drivers and optimizations.